In der Informatik ist ein Baum (engl. tree) eine Datenstruktur und ein abstrakter Datentyp, mit dem sich hierarchische Strukturen abbilden lassen. Dadurch, dass einerseits viele kombinatorische Probleme auf Bäume zurückgeführt werden können oder (im Fall von Spannbäumen) die Ergebnisse von Graphenalgorithmen (wie der Breiten- oder Tiefensuche) sind, spielen Bäume in der Informatik eine besondere Rolle. Dabei können ausgehend von der Wurzel mehrere gleichartige Objekte miteinander verkettet werden, sodass die lineare Struktur der Liste aufgebrochen wird und eine Verzweigung stattfindet. Da Bäume zu den meist verwendeten Datenstrukturen in der Informatik gehören, gibt es viele Spezialisierungen.
Definitionen
Bäume können auf verschiedene Weise definiert werden, z. B.
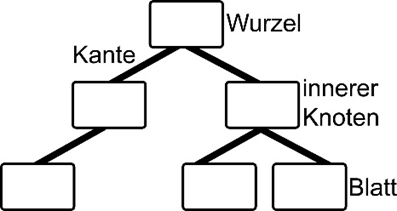
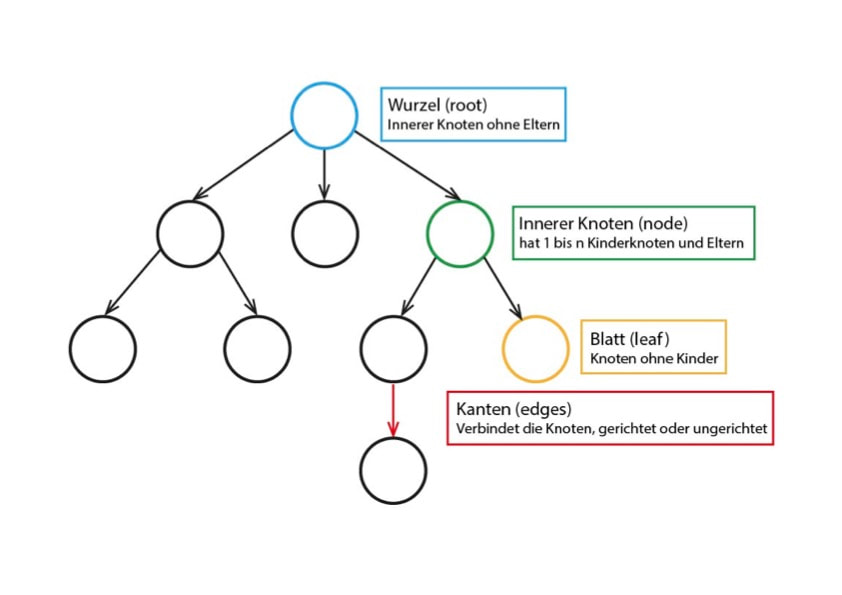
- Ein Baum besteht aus einer Menge von Knoten und einer Menge von Kanten, die jeweils zwei Knoten verbinden. Ein bestimmter Knoten des Baums wird als Wurzel bezeichnet. Jeder Knoten mit Ausnahme der Wurzel ist durch eine Kante mit genau einem anderen Knoten verbunden, wobei dieser Knoten der Elternteil von n ist. Ein eindeutiger Pfad verläuft von der Wurzel zu jedem Knoten. Wenn jeder Knoten im Baum maximal zwei untergeordnete Knoten (Kinder) hat, wird der Baum Binärbaum genannt.
- Ein Baum ist entweder leer oder besteht aus einer Wurzel und 0 oder mehr Teilbäumen, von denen jeder auch ein Baum ist. Die Wurzel jedes Teilbaums ist durch eine Kante mit der Wurzel des übergeordneten Baums verbunden. Dies ist eine rekursive Definition für Bäume.
Eigenschaften
Der Vorteil von Bäumen gegenüber linearen Strukturen wie Felder oder Listen ist der effiziente Zugriff. So erfolgt beispielsweise eine Suche nur in logarithmischer Zeit gegenüber linearer Zeit bei Feldern (zu Details vergleiche Artikel Binärsuche). Der Vorteil von Bäumen als Datenstruktur gegenüber Netzwerkstrukturen ist die geringe Anzahl der Kanten (Verbindungen), die gespeichert bzw. berücksichtigt werden müssen. Die Anzahl der Kanten des vollständigen Graphen entspricht der Dreieckszahl . Die Anzahl der Kanten in einem Baum mit der gleichen Anzahl von Knoten (Objekten) ist dagegen lediglich .
Bäume können wie andere Graphenstrukturen über eine Adjazenzliste oder -matrix bzw. über eine Inzidenzmatrix gespeichert werden.
Terminologie
Allgemein werden alle denkbaren Begriffe der Graphentheorie entlehnt. Die durch die Hierarchie vorgegebenen Objekte nennt man Knoten. Typischerweise speichert jeder Knoten ausgehend von einem ersten Knoten, der Wurzel, eine Liste von Verweisen auf die ihnen untergeordneten Knoten. Diese Verweise heißen Kanten. Eine Kante verbindet zwei Knoten, um anzuzeigen, dass zwischen ihnen eine Beziehung besteht. Jeder Knoten außer der Wurzel ist durch genau eine eingehende Kante von einem anderen Knoten verbunden. Die Wurzel des Baums ist der einzige Knoten im Baum, der keine eingehenden Kanten hat. Jeder Knoten kann mehrere ausgehende Kanten haben.
Es ist üblich, bei den untergeordneten Knoten von Kindern und bei dem verweisenden Knoten von einem Elternteil zu sprechen. Die Menge der Knoten, die eingehende Kanten von demselben Knoten haben, werden als Kinder dieses Knotens bezeichnet. Ein Knoten ist das Elternteil aller Knoten, mit denen er mit ausgehenden Kanten verbunden ist. Knoten im Baum, die Kinder desselben Elternteils sind, werden als Geschwister bezeichnet. Auch andere der Genealogie entlehnten Bezeichnungen werden verwendet. Hat ein Knoten selbst keine Kinder, nennt man ihn ein Blatt.
Insbesondere sind die Begriffe der Wurzelbäume relevant: Bei diesen Bäumen ist die Wurzel eindeutig bestimmt. Hat man eine Wurzel festgehalten, lassen sich zusätzlich zu den Begriffen, die man bei graphentheoretischen Bäumen schon hat – Abstand, Teilbaum, Knotengrad, Isomorphie –, noch Folgendes definieren: Die Tiefe eines Knotens gibt an, wie viele Kanten er von der Wurzel entfernt ist. Die Wurzel hat die Tiefe 0. Die Knoten mit derselben Tiefe bilden zusammen eine Ebene oder ein Niveau. Die Höhe eines Baumes ist dann die maximale Tiefe eines Knotens.
Ein Knoten ist ein grundlegender Bestandteil eines Baumes. Er kann einen Namen haben, der Schlüssel genannt wird. Ein Knoten kann auch zusätzliche Informationen enthalten. Diese zusätzlichen Informationen werden Nutzdaten genannt. Während die Nutzdateninformationen für viele Baumalgorithmen nicht von zentraler Bedeutung sind, sind sie in Anwendungen, die Bäume verwenden, häufig von entscheidender Bedeutung.
Ein Pfad ist eine geordnete Liste von Knoten, die durch Kanten verbunden sind. Ein Teilbaum ist eine zusammenhängende Menge von Knoten und Kanten, die aus einem übergeordneten Knoten und allen Nachkommen dieses übergeordneten Knotens bestehen und selbst einen Baum bildet. Die Kinder jedes Knotens sind die Wurzeln eines Teilbaums.
Binärbaum
Ein wichtiger Spezialfall ist der Binärbaum, in welchem jeder Knoten nur höchstens zwei Kinder haben darf. So beträgt bei Binärbäumen die Anzahl der Kinder höchstens zwei und in höhen-balancierten Bäumen gilt zusätzlich, dass sich die Höhen des linken und rechten Teilbaums an jedem Knoten nicht zu sehr unterscheiden.
Bei geordneten Bäumen, insbesondere Suchbäumen, sind die Elemente in der Baumstruktur geordnet abgelegt, sodass man schnell Elemente im Baum finden kann. Man unterscheidet hier weiter in binäre Suchbäume mit AVL-Bäumen als balancierte Version und B-Bäumen sowie einer Variante, den B*-Bäumen. Spezialisierungen von B-Bäumen sind wiederum 2-3-4-Bäume, welche oft als Rot-Schwarz-Bäume implementiert werden.
Ein Spezialfall der AVL-Bäume sind Fibonacci-Bäume. Sie werden vor allem bei Effizienzüberlegungen zu höhen-balancierten Bäumen, insbesondere AVL-Bäumen, als Extremfälle und Vergleichsobjekte herangezogen.
Nicht sortiert, aber „verschachtelt“ sind geometrische Baumstrukturen wie der R-Baum und seine Varianten. Hier werden nur diejenigen Teilbäume durchsucht, die sich mit dem angefragten Bereich überlappen.
Bäume sind in ihrem Aufbau zwar mehrdimensional jedoch in der Verkettung der Objekte oft unidirektional. Die Verkettung der gespeicherten Objekte beginnt bei der Wurzel des Baums und von dort in Richtung der Knoten des Baums.
Programmierung
Das folgende Beispiel in der Programmiersprache C# zeigt die Implementierung eines ungerichteten Graphen mit Adjazenzlisten. Der ungerichtete Graph wird als Klasse UndirectedGraph deklariert. Bei der Ausführung des Programms wird die Methode Main verwendet, die auf der Konsole ausgibt, ob der Graph ein Baum ist.
Siehe auch
- Baumdiagramm
- Feld (Datentyp)
- Liste (Datenstruktur)
- Menge (Datenstruktur)
- Stapelspeicher
- Warteschlange (Datenstruktur)
Einzelnachweise
Literatur
- Hartmut Ernst, Jochen Schmidt, Gerd Beneken: Grundkurs Informatik. Grundlagen und Konzepte für die erfolgreiche IT-Praxis – Eine umfassende, praxisorientierte Einführung, 5. Auflage, Springer, Wiesbaden 2015, S. 523–596
- Heinz-Peter Gumm, Manfred Sommer: Einführung in die Informatik, 10. Aufl., Oldenbourg, München 2013, S. 372–398